A typical workflow in many data science projects can be summarized in the following diagram.

Capturing Data and Data Cleaning, Munging, Wrangling
Collecting large amounts of data is a challenge by itself. It may involve querying data from web servers, databases, API’s, online repositories, etc. Data are often noisy and almost never clean. There are often missing data, or data incorrectly captured or stored. Also, not all data are equally useful and some cannot be used directly. They may need to be modified and transformed into more useful datasets. These are all challenges that have to be dealt with before cleaned and modified data can be used as an input in mathematical and statistical models. Dealing with these challenges became a part of data science, at least in its broader sense.
Exploratory Data Analysis (EDA)
After cleaning and modifying data, we would like to use them in statistical models in order to make predictions about the business or domain from which the data came. But, in order to determine which statistical models are appropriate to apply or which hypotheses about the business are reasonable to assume and test, it is important to get a first intuition about the data and see what they are telling us. For that purpose, we perform exploratory data analysis. We often visualize data by plotting various graphs, histograms, bar charts, pie charts etc., with different features, variables, or columns. This helps us get first impression and intuition, and discover signatures of interesting phenomena the data are telling us about.
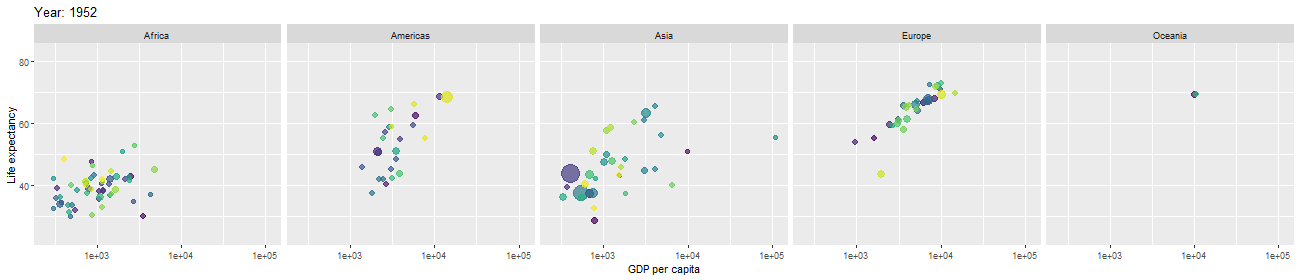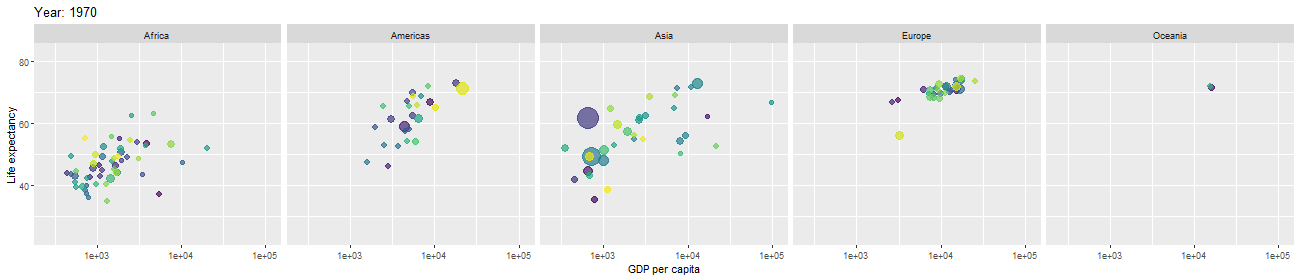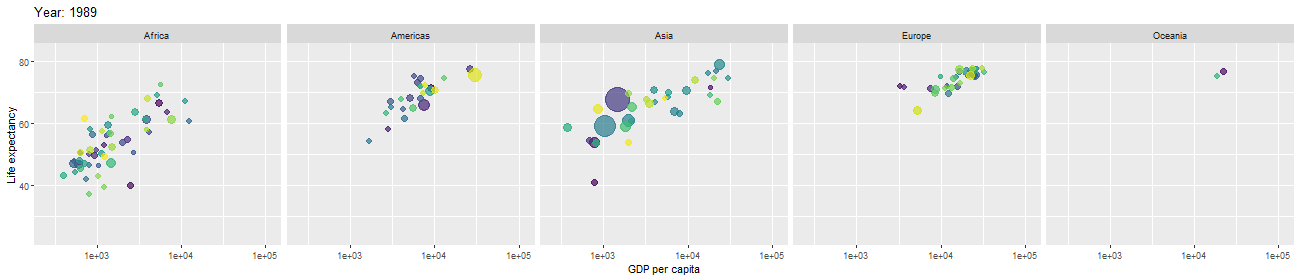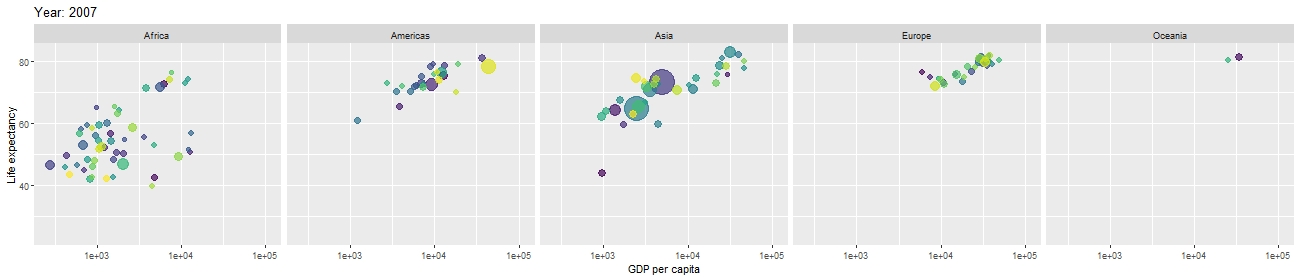
Mathematical and Statistical Modeling; Final Analysis
After visualizing data and getting intuition about what they show us, we can often raise some questions that need answers, and hypothesize certain claims about the data that need to be tested. We would also like to make predictions on future data. This is all done using mathematical and statistical modeling. That is, applying math and stats tools and methods on the cleaned data as inputs. This often requires an intensive programming/coding.

Reporting; Suggesting Actions
Once statistical methods were deployed and results and predictions were made, the report and/or presentation should be created. Conclusions are drawn and possibly some suggestions about future actions are given. This guides a decision making process in the corresponding business. Reports often contain a lot of visualization, graphs or animations. A report can be dynamic (generated by a code), so that when the whole code is run in future but using new data, the output of the report is automatically adjusted and modified. A report can also contain interactive apps, helping the readers and decision makers to better understand the results and findings by playing around with the apps.
After results were reported, decisions made and new actions undertaken in response to the analysis and suggestions, the outcome of these actions and the change that they cause can then be observed by collecting new data. This way a new iteration in the data science cycle can start in order to make further improvements in the business, and all the steps can be repeated.